Možná že jste si toho ani pořádně nestačili všimnout, ale pokud používáte nějakou službu od Seznam.cz, je prakticky jisté, že jste přišli do styku se „seznamáckou“ umělou inteligencí.
Česká portálová jednička vlastněná miliardářem Ivo Lukačovičem má v současnosti v provozu šestnáct produktů a funkcí postavených na generativní umělé inteligenci. Poslední společnost přidala v lednu, když přišla se sumarizací některých komplexních neinzertních výsledků vyhledávaných dotazů. Tím dokonce předběhla český Google, který podobnou funkci (AI Overviews) testuje zatím jen v zahraničí.
Seznam zatím takto odbavuje sice jen něco přes jedno procento celkového provozu své služby „Vyhledávání“ a službu si nelze vynutit, ale do budoucna se s ní a dalšími druhy souhrnů máme setkávat podstatně častěji.
Jen o týden později přidal Seznam také automatická AI shrnutí článků ze své homepage bez nutnosti jejich otevření, přehled nejdiskutovanějších témat v diskusích (funkce Top narativy) a vysvětlení, proč konkrétní dotazy trendují v pomyslném srdci Seznam.cz, tedy v enginu jeho Vyhledávání (funkce Trending topics).
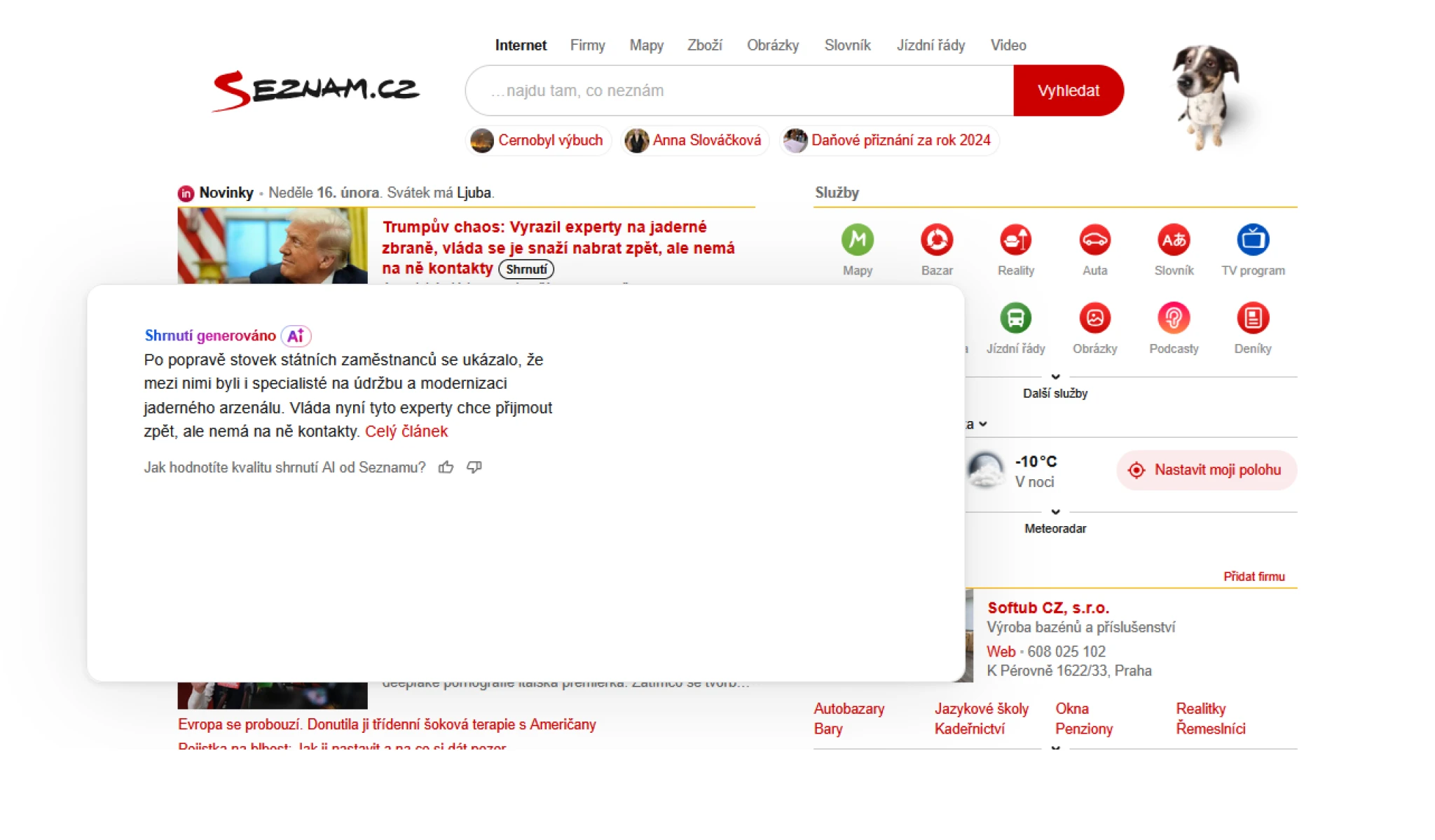
Shrnutí, které patří momentálně k nejviditelnějším AI funkcím Seznamu, funguje tak, že jazykový model přečte článek a připraví z něj krátké shrnutí, které se zobrazí po umístění myši vedle titulku článku. Funkce ale bohužel zatím nefunguje na mobilních zařízeních a Seznam ji pouští jen na vlastní texty, takže si ji neužijete u článků z partnerských webů.
Funkce shrnutí na home pagi Seznamu
Již v průběhu loňského roku mohli uživatelé také narazit například na umělou inteligenci, která jim předpřipraví inzerát, a začátkem prosince začaly nástroje Seznamu sumarizovat veškeré diskuse na této platformě.
Nejlepší na tom celém ale je, že nejde o funkce postavené na komerčních modelech třetích stran, jako je například OpenAI, ale na vlastních velkých jazykových modelech, které Seznam žertovně pojmenoval SeLLMa (Šelma).
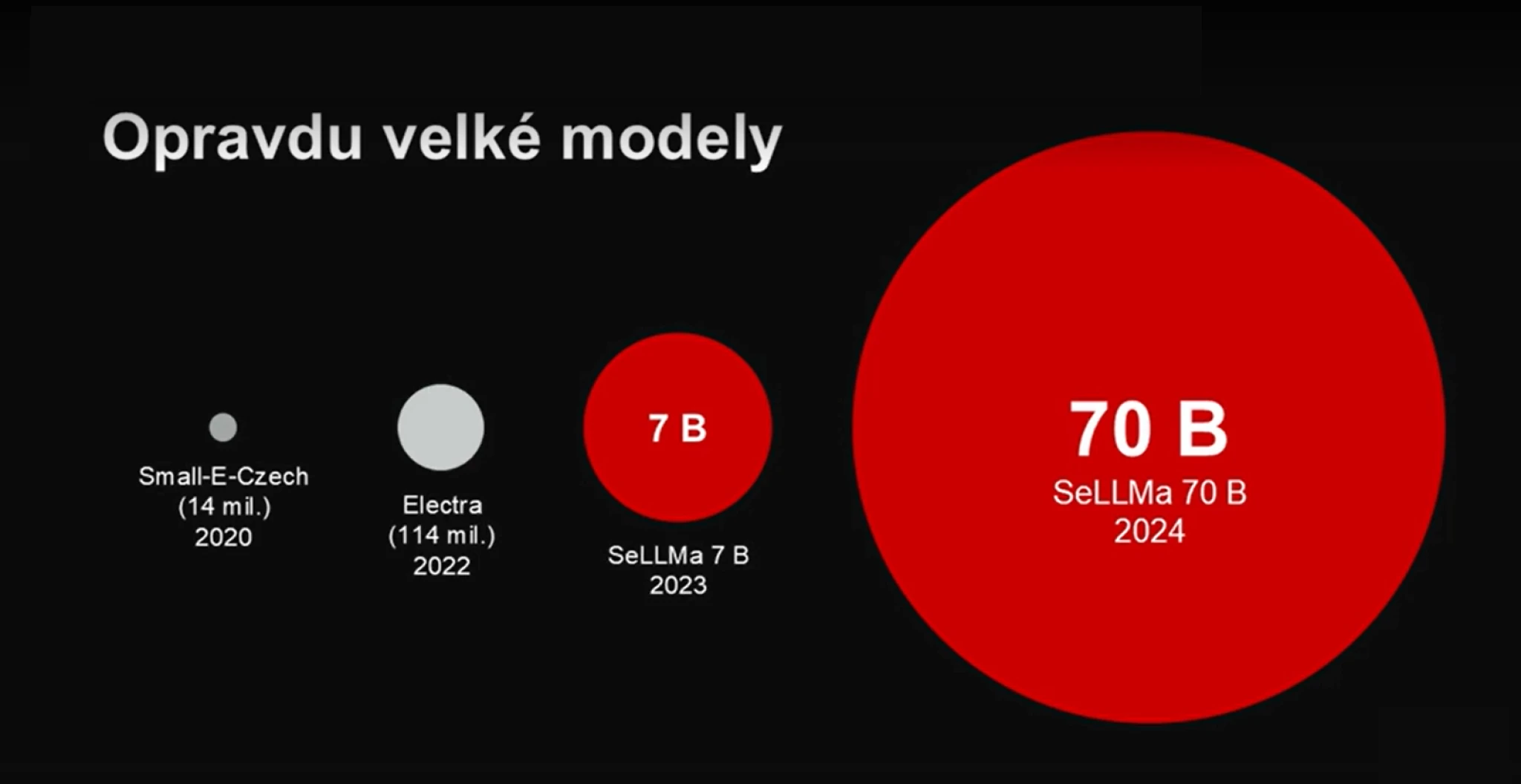
Název vznikl jako slovní hříčka ze slov Seznam a LLM (velký jazykový model). Ty se liší především svou velikostí, přičemž ten největší přiznaný disponuje sedmdesáti miliardami parametrů.
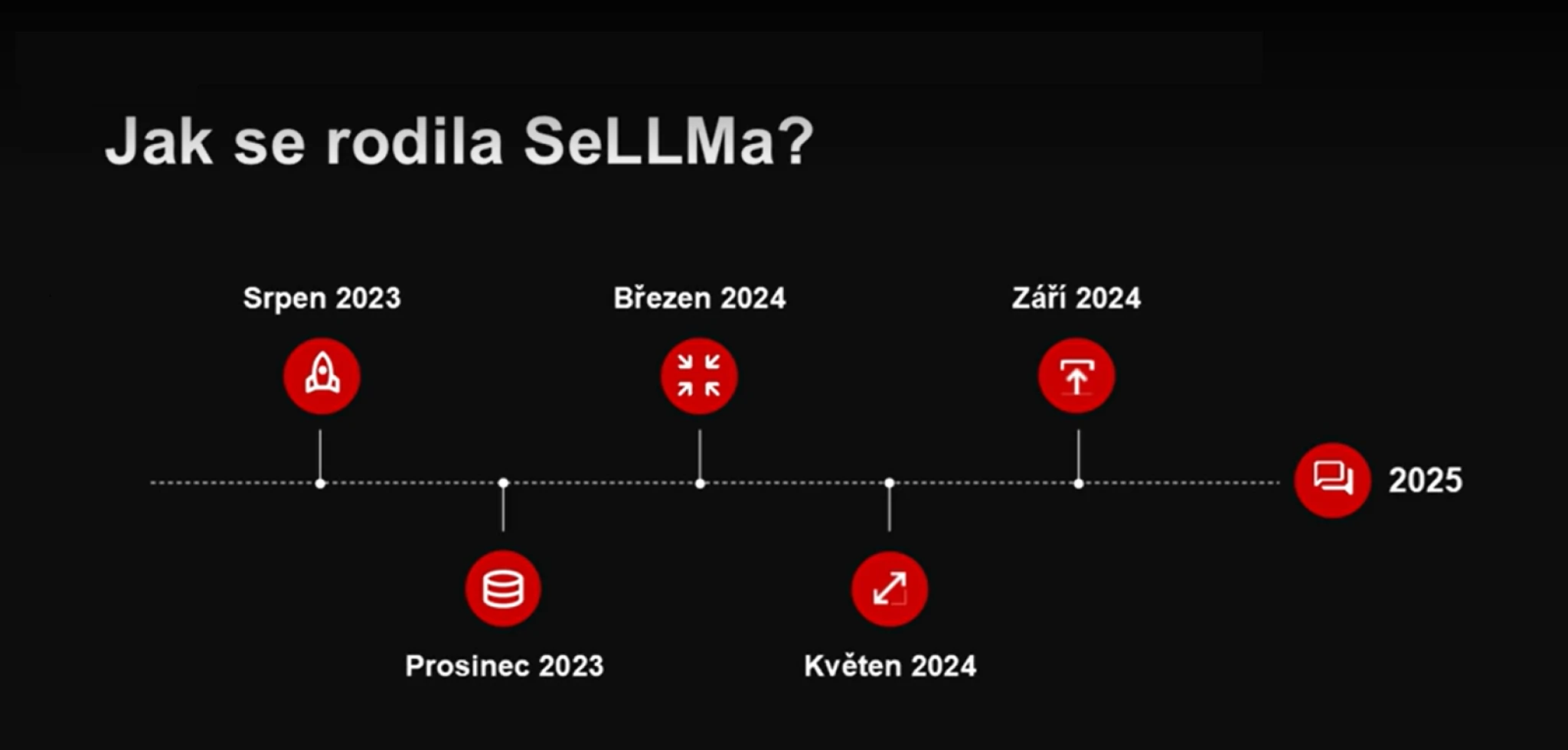
Modely nejsou postaveny úplně od pomyslné nuly, ačkoli menší jazykové modely už v Seznamu v minulosti vznikly, ale vycházejí z open source modelů LLaMa (verze 3.1) od Mety a také open source modelů Mistral francouzského AI jednorožce, společnosti Mistral AI, které Seznam takzvaně dotrénoval pomocí metody zvané „continued pretraining“.
Zdroj: Seznam.cz
Jejich velkou výhodou má být to, že se učí na firemních datech, údajně s extrémním důrazem na bezpečnost a ochranu zdrojů – modely si firma pochopitelně provozuje plně ve vlastní režii – a hlavně na rozsáhlém českém jazykovém korpusu.
Výsledkem je tak špičková čeština modelů, která dnes překonává přinejmenším GPT-3.5. Ten na druhé straně již nějaký čas nepředstavuje úplně oborový benchmark.
Zdroj: Seznam.cz
Firma si na jejich trénink již dříve nakoupila stovky výkonných jader H100 a L4 od Nvidie, zaměstnala vývojem a tréninkem přibližně padesát zaměstnanců s podporou dalších dvou set lidí v rámci firmy a do loňského podzimu stačila utratit částku přesahující sto milionů korun.
„Jen na možnosti zobrazit shrnutí článku s pomocí AI jsme pracovali více než rok. Samo o sobě to není pro SeLLMu složitý úkol, ale zajistit, aby vše fungovalo automaticky bez zásahu editora a přešlapů běžně spojených s generativními modely, bylo složitější,“ okomentoval letošní spuštění funkce souhrnů článků Marek Vacek, produktový manažer domovské stránky Seznam.cz.
Uvidíme, co dalšího na nás Seznam se svou umělou inteligencí letos chystá a jestli zvládne držet krok se stále rychlejším globálním vývojem v této oblasti.